目录
- 1.5.2 ZFNet
- 5.7 反卷积(Deconvnet)
- 5.7.1 上采样池化(UnPooling)
- 5.7.2 反卷积过程
- 5.8 ZFNet 架构设计
- 5.9 ZFNet 的贡献
1.5.2 ZFNet
在前文中,我们对 AlexNet 的架构以及核心组件做了相关介绍,虽然 AlexNet 赢得了 ILSVRC2012 的冠军,相比传统技术取得辉煌的成就,然而技术绝不止步于此,AlexNet 为什么性能如此优越,它还能如何改进呢?带着这样的问题,在 ILSVRC2013 中,ZFNet1 利用反卷积可视化技术探讨上述问题,并对 AlexNet 网络加以改进,改进后的 ZFNet 性能已明显超越 AlexNet。
ZFNet 由 Matthew D. Zeiler 和他的博导 Rob Fergus 提出,网络命名来自于他们的名字首字母组合。ZFNet 实际上并不是这一届的冠军,而是由一个创业公司 Clarifai 获得,而 Zeiler 是该公司的 CEO,而我们通常讨论 ILSVRC2013 的获胜者,一般也指的是 ZFNet。
5.7 反卷积(Deconvnet)
在深度学习中提到的反卷积通常是指转置卷积(transposed convolution),卷积操作的一般步骤通常是将输入层的图像经过某个卷积核实现卷积操作,将其映射到输出空间中。而反卷积操作则是将输出空间的数据反向应用该卷积核,将其映射到输入像素空间中,这样在输入层的成像可以表明该卷积核从中提取了什么特征模式。
网络正向卷积的过程可以简化为:卷积、ReLU非线性激活、池化。则反卷积过程可以简化为反池化、ReLU非线性激活、反卷积。如下图所示,右侧自下而上是图像的正向卷积过程,左侧自上而下是反卷积过程。
 【图 1】
【图 1】
5.7.1 上采样池化(UnPooling)
通常在卷积网络中的池化是指下采样(DownPooling)过程,而一般的池化网格为 2 × 2 2\times 2 2×2,如下图所示,最大池化是指在 2 × 2 2 \times 2 2×2 的单元格中挑选最大的数值,这个过程中,图像的高度和宽度均缩小一半,因此称为下采样,而上采样是将特征图在高度和宽度上放大一倍的操作,因此称之为上采样。然而从下采样到上采样,该过程是不可逆的,因此在执行下采样的期间需要记录单元格中最大局部值(max locations)的位置,以便用于上采样过程,其补充的新空间位置一般补 0。整个过程如下图所示:
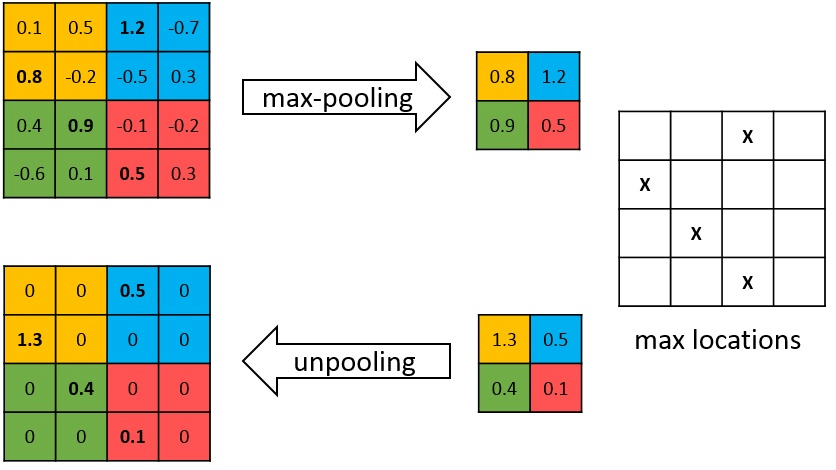 【图 2】
【图 2】
在卷积过程中,我们使用 ReLU 激活函数保证所有的输出均为非负数,这个约束对于反卷积过程依然适用,这样映射到输入像素空间的图像值也均为非负,因此在反卷积过程中我们依然使用 ReLU 激活函数。
5.7.2 反卷积过程
如图 1 所示,在卷积过程中,我们使用的卷积核为 F F F,而在反卷积过程中,我们使用的卷积核为 F T F^T FT。这就是为什么此类的反卷积也被称为转置卷积。为了更好的理解转置过程,我们举例如下:
假设某特征图为 X = [ 1 2 3 4 5 6 7 8 9 ] X=\begin{bmatrix} 1 & 2 & 3\\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix} X=⎣⎡147258369⎦⎤,卷积核 F = [ 1 2 1 2 1 3 3 1 2 ] F=\begin{bmatrix} 1 & 2 & 1\\ 2 & 1 & 3 \\ 3 & 1 & 2 \end{bmatrix} F=⎣⎡123211132⎦⎤,则卷积后的特征图为 [ 86 ] \begin{bmatrix} 86 \end{bmatrix} [86],一个 3 × 3 3 \times 3 3×3 的特征图与 3 × 3 3 \times 3 3×3 的卷积核操作得到 1 × 1 1 \times 1 1×1 大小的特征图,而反卷积是将得到的 1 × 1 1 \times 1 1×1 的特征图利用该卷积核还原为原始 3 × 3 3 \times 3 3×3 的特征图。为此,我们首先需要将 1 × 1 1\times 1 1×1 的卷积核扩展为 5 × 5 5\times 5 5×5,这样在与 3 × 3 3\times 3 3×3 大小的卷积核卷积后得到的图像大小为 3 × 3 3 \times 3 3×3。操作过程如下:
[ 0 0 0 0 0 0 0 0 0 0 0 0 86 0 0 0 0 0 0 0 0 0 0 0 0 ] ∗ [ 2 1 3 3 1 2 1 2 1 ] = [ 1 2 3 4 5 6 7 8 9 ] × 86 \begin{bmatrix} 0 & 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 86 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\0 & 0 & 0 & 0 & 0 \end{bmatrix} * \begin{bmatrix} 2 & 1 & 3\\ 3 & 1 & 2 \\ 1 & 2 & 1 \end{bmatrix} = \begin{bmatrix} 1 & 2 & 3\\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix}\times 86 ⎣⎢⎢⎢⎢⎡00000000000086000000000000⎦⎥⎥⎥⎥⎤∗⎣⎡231112321⎦⎤=⎣⎡147258369⎦⎤×86
在上述过程中,我们可以看到此处的卷积核实际为原卷积核 F F F 的转置。
5.8 ZFNet 架构设计
借助反卷积可视化技术,可以查看 AlexNet 卷积网络中存在的一些问题:
- AlexNet 网络第一层卷积核混杂了大量的高频和低频信号,但是缺乏中频信息
- AlexNet 第二卷积层跨度过大,产生了一些混叠失真等无意义特征
针对这两个缺陷,ZFNet 将 AlexNet 第一层的卷积核由 11 × 11 11\times 11 11×11 减小为 7 × 7 7 \times 7 7×7,强迫网络从更小的局部范围抽取特征,避免对中频信息的严重过滤,其次将 AlexNet 第一层的卷积步长由 4 降低为 2。
| 模块 | 卷积层 | 池化、正则 |
|---|---|---|
| CONV1 | [7×7 ~ 2 | 3→96] | MAXPOOL[3×3 ~ 2]→LRN |
| CONV2 | [5×5 ~ 2 | 96→256] | MAXPOOL[3×3 ~ 2]→LRN |
| CONV3 | [3×3 ~ 1 | 256→384] | →LRN |
| CONV4 | [3×3 ~ 1 | 384→384] | →LRN |
| CONV5 | [3×3 ~ 1 | 384→256] | MAXPOOL[3×3 ~ 2]→LRN |
| FC1 | [12544→4096] | DROPOUT 50% |
| FC2 | [4096→4096] | DROPOUT 50% |
| Softmax | [4096→1000] |
5.9 ZFNet 的贡献
通过上面的介绍,我们知道 ZFNet 仅仅是 AlexNet 的一个微型改版,该网络本身的架构在目前的 CNN 家族中几乎被湮没了。然而抛开本身的网络架构,其可视化理解 CNN 网络的思路以及实验结果却对 CNN 架构的发展起到了至关重要的作用:
- 通过对各层卷积核的可视化,我们可以直观的看出 CNN 网络各层的特征提取情况,底层主要对物理轮廓、边缘、纹理、颜色等特征进行提取,而高层逐渐通过低层的特征组合为具有明显分类性质的抽象特征,这表明 CNN 网络的高层与特定的分类任务有关,而低层卷积架构则可以理解为通用特征提取器,这也是预训练+微调模式的重要理论依据。
- 在对图像进行一些位移、缩放及旋转操作后,实验证明 CNN 特征提取器检测到的特征具有平移和缩放不变性,但是不具有旋转不变性。
- 在对网络架构的全连接层和卷积层进行增删等可以发现,全连接层对结果的影响较小但是增加一些卷积层会有一定的性能提升,这将作为一个 CNN 深度架构时代的开端,由此引发一场深度架构大战。
Visualizing and Understanding Convolutional Networks ↩︎